
Now we will see how to Extract Alibaba Product data using Python and BeautifulSoup in a simple and elegant manner.
The purpose of this blog is to start solving many problems by keeping them simple so you will get familiar and get practical results as fast as possible.
Initially, you need to install Python 3. If you haven’t done, then please install Python 3 before you continue.
You can mount Beautiful Soup with:
pip3 install beautifulsoup4
We also require the library's needs soup sieve, lxml, and to catch data, break down to XML, and utilize CSS selectors.
pip3 install requests soupsieve lxml
Once it is installed you need to open the editor and type in:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
Now go to the Alibaba list page and look over the details we need to get.
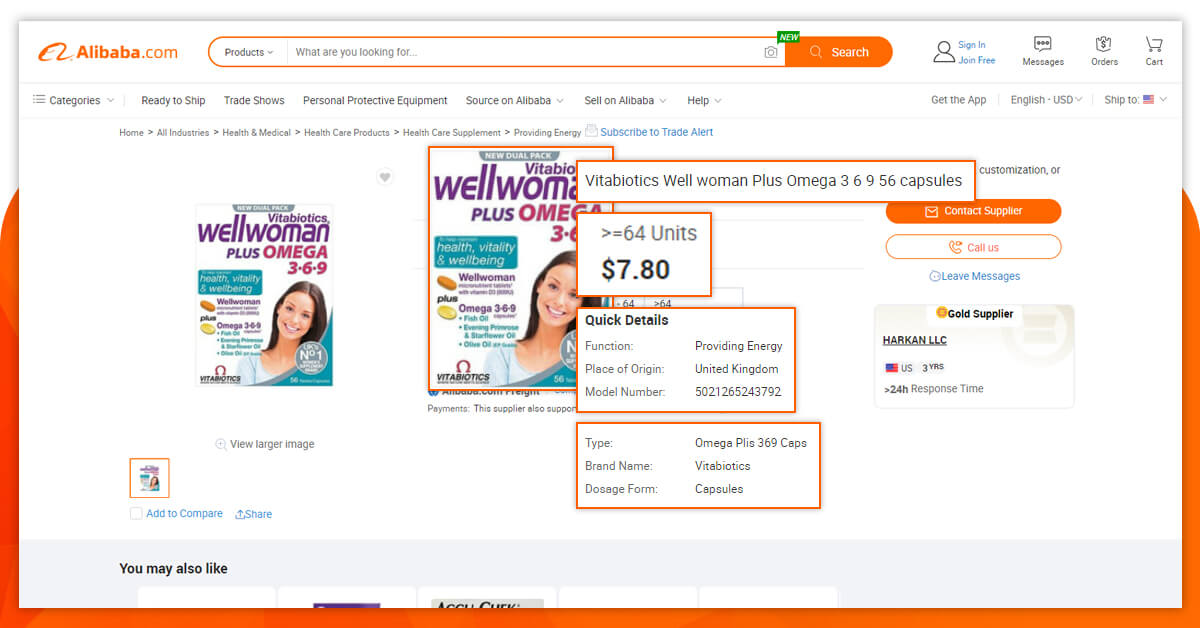
Get back to code. Let’s acquire and try that information by imagining we are also a browser like this:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requestsheaders = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.alibaba.com/catalog/power-tools_cid1417?spm=a2700.7699653.scGlobalHomeHeader.548.7bc23e5fdb6651'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
Save this as scrapeAlibaba.py
If you run it.
python3 scrapeAlibaba.py
You will be able to see the entire HTML side.
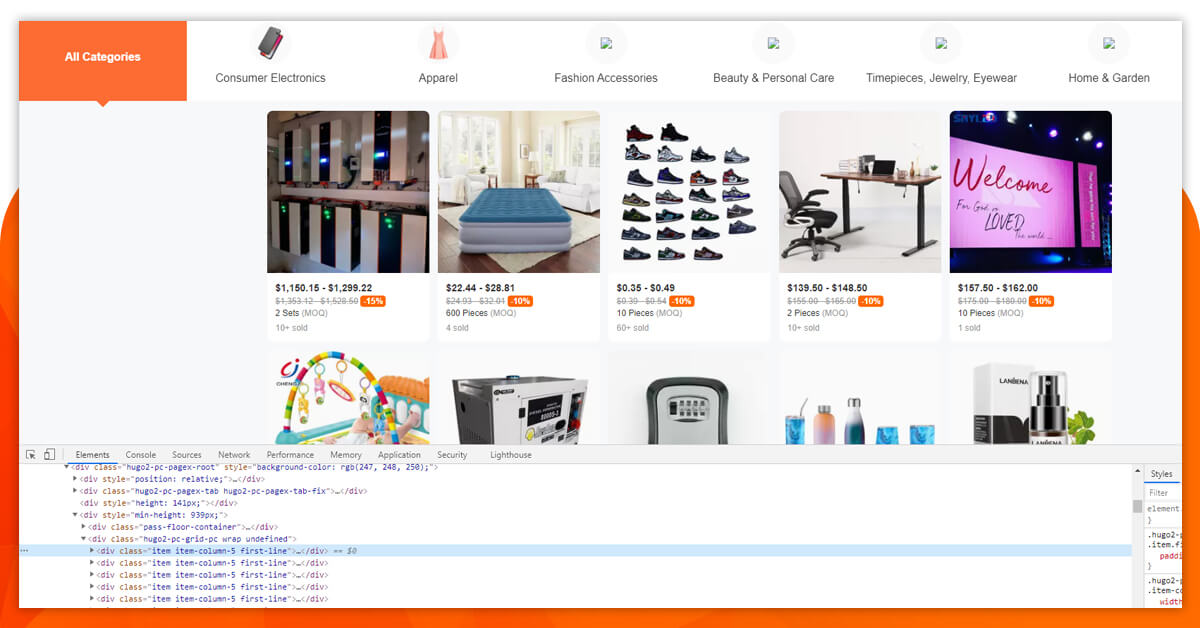
Now, let’s utilize CSS selectors to get the data you require. To ensure that you need to go to Chrome and open the review tool.
Want to extract Alibaba product data?
Request a Quote!
We observe all the specific product data contains a class ‘organic-gallery-offer-outter’. We scrape this with the CSS selector ‘. organic-gallery-offer-outter’ effortlessly. Here is the code, let’s see how it will look like:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requestsheaders = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.alibaba.com/catalog/power-tools_cid1417?spm=a2700.7699653.scGlobalHomeHeader.548.7bc23e5fdb6651'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')#print(soup.select('[data-lid]'))
for item in soup.select('.organic-gallery-offer-outter'):
try:
print('----------------------------------------')
print(item) except Exception as e:
#raise e
print('')
This will print all the remaining content in every container that clutches the product information.
We can choose the classes inside the given row that holds the information we require.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requestsheaders = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.alibaba.com/catalog/power-tools_cid1417?spm=a2700.7699653.scGlobalHomeHeader.548.7bc23e5fdb6651'response=requests.get(url,headers=headers)soup=BeautifulSoup(response.content,'lxml')#print(soup.select('[data-lid]'))
for item in soup.select('.organic-gallery-offer-outter'):
try:
print('----------------------------------------')
print(item) print(item.select('.organic-gallery-title__content')[0].get_text().strip())
print(item.select('.gallery-offer-price')[0].get_text().strip())
print(item.select('.gallery-offer-minorder')[0].get_text().strip())
print(item.select('.seb-supplier-review__score')[0].get_text().strip())
print(item.select('[flasher-type=supplierName]')[0].get_text().strip())
print(item.select('.seb-img-switcher__imgs img')[0]['src'])
except Exception as e:
#raise e
print('')
Once it is run, it will print all the information.
If you need to use this product and want to scale millions of links, then you will see that your IP is getting blocked by Copy Blogger. In this situation use a revolving proxy service to rotate IPs is necessary. You can use a service like Proxies API to track your calls via millions of inhabited proxies.
If you need to measure the crawling pace or you don’t need to set up your structure, you can easily utilize our Cloud base crawler. So that you can easily crawl millions of URLs at a high pace from crawlers.
If you are looking for Alibaba Product Data Scraping Services, then you can contact Web Screen Scraping for all your queries.