
The travel industry is a huge business, set to grow exponentially in coming years. It revolves around movement of people from one place to another, encompassing the various amenities and accommodations they need during their travels. This concept shares a strong connection with sectors such as hospitality and the hotel industry.
Here, it becomes prudent to mention Airbnb. Airbnb stands out as a well-known online platform that empowers people to list, explore, and reserve lodging and accommodation choices, typically in private homes, offering an alternative to the conventional hotel and inn experience.
Scraping Airbnb listings data entails the process of retrieving or collecting data from Airbnb property listings. To Scrape Data from Airbnb's website successfully, you need to understand how Airbnb's listing data works. This blog will guide us how to scrape Airbnb listing data.
What Is Airbnb Scraping?

Airbnb serves as a well-known online platform enabling individuals to rent out their homes or apartments to travelers. Utilizing Airbnb offers advantages such as access to extensive property details like prices, availability, and reviews.
Data from Airbnb is like a treasure trove of valuable knowledge, not just numbers and words. It can help you do better than your rivals. If you use the Airbnb scraper tool, you can easily get this useful information.
Effectively scraping Airbnb’s website data requires comprehension of its architecture. Property information, listings, and reviews are stored in a database, with the website using APIs to fetch and display this data. To scrape the details, one must interact with these APIs and retrieve the data in the preferred format.
In essence, Airbnb listing scraping involves extracting or scraping Airbnb listings data. This data encompasses various aspects such as listing prices, locations, amenities, reviews, and ratings, providing a vast pool of data.
What Are the Types of Data Available on Airbnb?
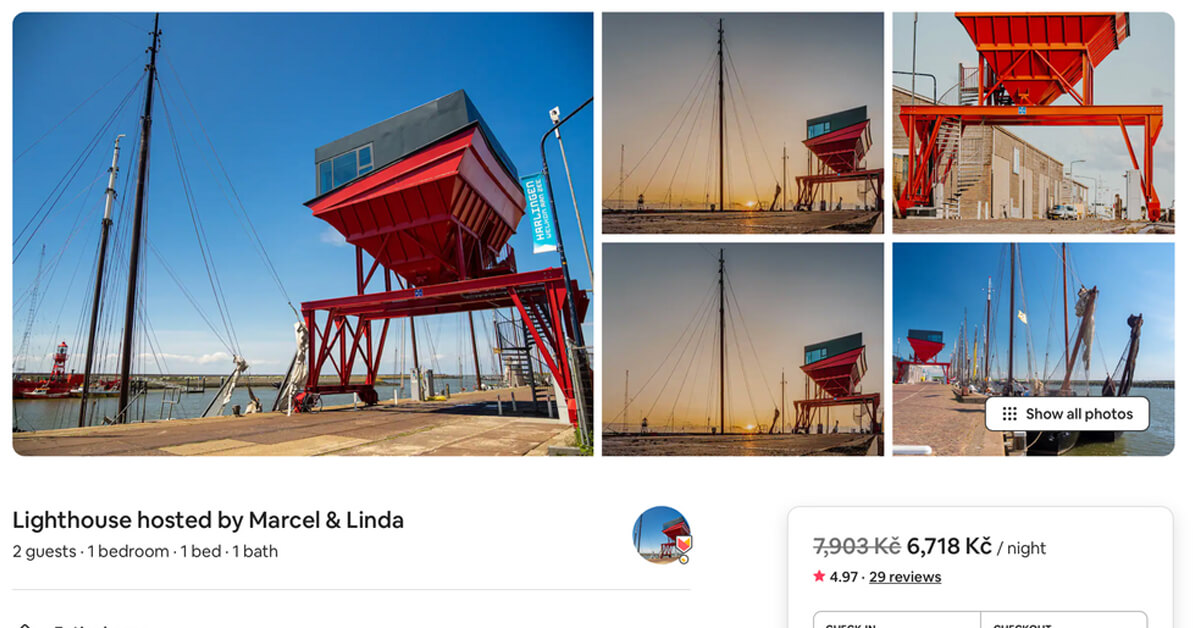
Navigating via Airbnb's online world uncovers a wealth of data. To begin with, property details, like data such as the property type, location, nightly price, and the count of bedrooms and bathrooms. Also, amenities (like Wi-Fi, a pool, or a fully-equipped kitchen) and the times for check-in and check-out. Then, there is data about the hosts and guest reviews and details about property availability.
Here's a simplified table to provide a better overview:
| Type of Data | What it Contains |
|---|---|
| Property Details | Data regarding the property, including its category, location, cost, number of rooms, available features, and check-in/check-out schedules. |
| Host Information | Information about the property's owner, encompassing their name, response time, and the number of properties they oversee. |
| Guest Reviews | Ratings and written feedback from previous property guests. |
| Booking Availability | Data on property availability, whether it's available for booking or already booked, and the minimum required stay. |
Why Is the Airbnb Data Important?
Extracting data from Airbnb has many advantages for different reasons:
Market Research
Scraping Airbnb listing data helps you gather information about the rental market. You can learn about prices, property features, and how often places get rented. It is useful for understanding the market, finding good investment opportunities, and knowing what customers like.
Getting to Know Your Competitor
By scraping Airbnb listings data, you can discover what other companies in your industry are doing. You'll learn about their offerings, pricing, and customer opinions.
Evaluating Properties
Scraping Airbnb listing data lets you look at properties similar to yours. You can see how often they get booked, what they charge per night, and what guests think of them. It helps you set the prices right, make your property better, and make guests happier.
Smart Decision-Making
With scraped Airbnb listing data, you can make smart choices about buying properties, managing your portfolio, and deciding where to invest. The data can tell you which places are popular, what guests want, and what is trendy in the vacation rental market.
Personalizing and Targeting
By analyzing scraped Airbnb listing data, you can learn what your customers like. You can find out about popular features, the best neighborhoods, or unique things guests want. Next, you can change what you offer to fit what your customers like.
Automating and Saving Time
Instead of typing everything yourself, web scraping lets a computer do it for you automatically and for a lot of data. It saves you time and money and ensures you have scraped Airbnb listing data.
Is It Legal to Scrape Airbnb Data?
Collecting Airbnb listing data that is publicly visible on the internet is okay, as long as you follow the rules and regulations. However, things can get stricter if you are trying to gather data that includes personal info, and Airbnb has copyrights on that.
Most of the time, websites like Airbnb do not let automatic tools gather information unless they give permission. It is one of the rules you follow when you use their service. However, the specific rules can change depending on the country and its policies about automated tools and unauthorized access to systems.
How To Scrape Airbnb Listing Data Using Python and Beautiful Soup?

Websites related to travel, like Airbnb, have a lot of useful information. This guide will show you how to scrape Airbnb listing data using Python and Beautiful Soup. The information you collect can be used for various things, like studying market trends, setting competitive prices, understanding what guests think from their reviews, or even making your recommendation system.
We will use Python as a programming language as it is perfect for prototyping, has an extensive online community, and is a go-to language for many. Also, there are a lot of libraries for basically everything one could need. Two of them will be our main tools today:
- Beautiful Soup — Allows easy scraping of data from HTML documents
- Selenium — A multi-purpose tool for automating web-browser actions
Getting Ready to Scrape Data
Now, let us think about how users scrape Airbnb listing data. They start by entering the destination, specify dates then click "search." Airbnb shows them lots of places.
This first page is like a search page with many options. But there is only a brief data about each.
After browsing for a while, the person clicks on one of the places. It takes them to a detailed page with lots of information about that specific place.
We want to get all the useful information, so we will deal with both the search page and the detailed page. But we also need to find a way to get info from the listings that are not on the first search page.
Usually, there are 20 results on one search page, and for each place, you can go up to 15 pages deep (after that, Airbnb says no more).
It seems quite straightforward. For our program, we have two main tasks:
looking at a search page, and getting data from a detailed page.
So, let us begin writing some code now!
Getting the listings
Using Python to scrape Airbnb listing data web pages is very easy. Here is the function that extracts the webpage and turns it into something we can work with called Beautiful Soup.
def scrape_page(page_url):
"""Extracts HTML from a webpage"""
answer = requests.get(page_url)
content = answer.content
soup = BeautifulSoup(content, features='html.parser')
return soup
Beautiful Soup helps us move around an HTML page and get its parts. For example, if we want to take the words from a “div” object with a class called "foobar" we can do it like this:
text = soup.find("div", {"class": "foobar"}).get_text()
On Airbnb's listing data search page, what we are looking for are separate listings. To get to them, we need to tell our program which kinds of tags and names to look for. A simple way to do this is to use a tool in Chrome called the developer tool (press F12).
The listing is inside a "div" object with the class name "8s3ctt." Also, we know that each search page has 20 different listings. We can take all of them together using a Beautiful Soup tool called "findAll."
def extract_listing(page_url):
"""Extracts listings from an Airbnb search page"""
page_soup = scrape_page(page_url)
listings = page_soup.findAll("div", {"class": "_8s3ctt"})
return listings
Getting Basic Info from Listings
When we check the detailed pages, we can get the main info about the Airbnb listings data, like the name, total price, average rating, and more.
All this info is in different HTML objects as parts of the webpage, with different names. So, we could write multiple single extractions -to get each piece:
name = soup.find('div', {'class':'_hxt6u1e'}).get('aria-label')
price = soup.find('span', {'class':'_1p7iugi'}).get_text()
...
However, I chose to overcomplicate right from the beginning of the project by creating a single function that can be used again and again to get various things on the page.
def extract_element_data(soup, params):
"""Extracts data from a specified HTML element"""
# 1. Find the right tag
if 'class' in params:
elements_found = soup.find_all(params['tag'], params['class'])
else:
elements_found = soup.find_all(params['tag'])
# 2. Extract text from these tags
if 'get' in params:
element_texts = [el.get(params['get']) for el in elements_found]
else:
element_texts = [el.get_text() for el in elements_found]
# 3. Select a particular text or concatenate all of them
tag_order = params.get('order', 0)
if tag_order == -1:
output = '**__**'.join(element_texts)
else:
output = element_texts[tag_order]
return output
Now, we've got everything we need to go through the entire page with all the listings and collect basic details from each one. I'm showing you an example of how to get only two details here, but you can find the complete code in a git repository.
RULES_SEARCH_PAGE = {
'name': {'tag': 'div', 'class': '_hxt6u1e', 'get': 'aria-label'},
'rooms': {'tag': 'div', 'class': '_kqh46o', 'order': 0},
}
listing_soups = extract_listing(page_url)
features_list = []
for listing in listing_soups:
features_dict = {}
for feature in RULES_SEARCH_PAGE:
features_dict[feature] = extract_element_data(listing, RULES_SEARCH_PAGE[feature])
features_list.append(features_dict)
Getting All the Pages for One Place
Having more is usually better, especially when it comes to data. Scraping Airbnb listing data lets us see up to 300 listings for one place, and we are going to scrape them all.
There are different ways to go through the pages of search results. It is easiest to see how the web address (URL) changes when we click on the "next page" button and then make our program do the same thing.
All we have to do is add a thing called "items_offset" to our initial URL. It will help us create a list with all the links in one place.
def build_urls(url, listings_per_page=20, pages_per_location=15):
"""Builds links for all search pages for a given location"""
url_list = []
for i in range(pages_per_location):
offset = listings_per_page * i
url_pagination = url + f'&items_offset={offset}'
url_list.append(url_pagination)
return url_list
We have completed half of the job now. We can run our program to gather basic details for all the listings in one place. We just need to provide the starting link, and things are about to get even more exciting.
Dynamic Pages
It takes some time for a detailed page to fully load. It takes around 3-4 seconds. Before that, we could only see the base HTML of the webpage without all the listing details we wanted to collect.
Sadly, the "requests" tool doesn't allow us to wait until everything on the page is loaded. But Selenium does. Selenium can work just like a person, waiting for all the cool website things to show up, scrolling, clicking buttons, filling out forms, and more.
Now, we plan to wait for things to appear and then click on them. To get information about the amenities and price, we need to click on certain parts.
To sum it up, here is what we are going to do:
- Start up Selenium.
- Open a detailed page.
- Wait for the buttons to show up.
- Click on the buttons.
- Wait a little longer for everything to load.
- Get the HTML code.
Let us put them into a Python function.
def extract_soup_js(listing_url, waiting_time=[5, 1]):
"""Extracts HTML from JS pages: open, wait, click, wait, extract"""
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
driver = webdriver.Chrome(options=options)
driver.get(listing_url)
time.sleep(waiting_time[0])
try:
driver.find_element_by_class_name('_13e0raay').click()
except:
pass # amenities button not found
try:
driver.find_element_by_class_name('_gby1jkw').click()
except:
pass # prices button not found
time.sleep(waiting_time[1])
detail_page = driver.page_source
driver.quit()
return BeautifulSoup(detail_page, features='html.parser')
Now, extracting detailed info from the listings is quite straightforward because we have everything we need. All we have to do is carefully look at the webpage using a tool in Chrome called the developer tool. We write down the names and names of the HTML parts, put all of that into a tool called "extract_element_data.py" and we will have the data we want.
Running Multiple Things at Once
Getting info from all 15 search pages in one location is pretty quick. When we deal with one detailed page, it takes about just 5 to 6 seconds because we have to wait for the page to fully appear. But, the fact is the CPU is only using about 3% to 8% of its power.
So. instead of going to 300 webpages one by one in a big loop, we can split the webpage addresses into groups and go through these groups one by one. To find the best group size, we have to try different options.
from multiprocessing import Pool
with Pool(8) as pool:
result = pool.map(scrape_detail_page, url_list)
The Outcome
After turning our tools into a neat little program and running it for a location, we obtained our initial dataset.
The challenging aspect of dealing with real-world data is that it's often imperfect. There are columns with no information, many fields need cleaning and adjustments. Some details turned out to be not very useful, as they are either always empty or filled with the same values.
There's room for improving the script in some ways. We could experiment with different parallelization approaches to make it faster. Investigating how long it takes for the web pages to load can help reduce the number of empty columns.
To Sum It Up
We've mastered:
- Scraping Airbnb listing data using Python and Beautiful Soup.
- Handling dynamic pages using Selenium.
- Running the script in parallel using multiprocessing.
Conclusion
Web scraping today offers user-friendly tools, which makes it easy to use. Whether you are a coding pro or a curious beginner, you can start scraping Airbnb listing data with confidence. And remember, it's not just about collecting data – it's also about understanding and using it.
The fundamental rules remain the same, whether you're scraping Airbnb listing data or any other website, start by determining the data you need. Then, select a tool to collect that data from the web. Finally, verify the data it retrieves. Using this info, you can make better decisions for your business and come up with better plans to sell things.
So, be ready to tap into the power of web scraping and elevate your sales game. Remember that there's a wealth of Airbnb data waiting for you to explore. Get started with an Airbnb scraper today, and you'll be amazed at the valuable data you can uncover. In the world of sales, knowledge truly is power.