
What is Product Data?

Before we deep dive into Amazon Web Scraping, let us first establish our understanding of the basics, which comes down to product data. Any information about a product that you can read, measure, and transform into a functional format is product data. When we talk about the data of a product, we look at features like price and identifier.
Why scrape Amazon Product Data? What kind of product data can be scraped from Amazon?
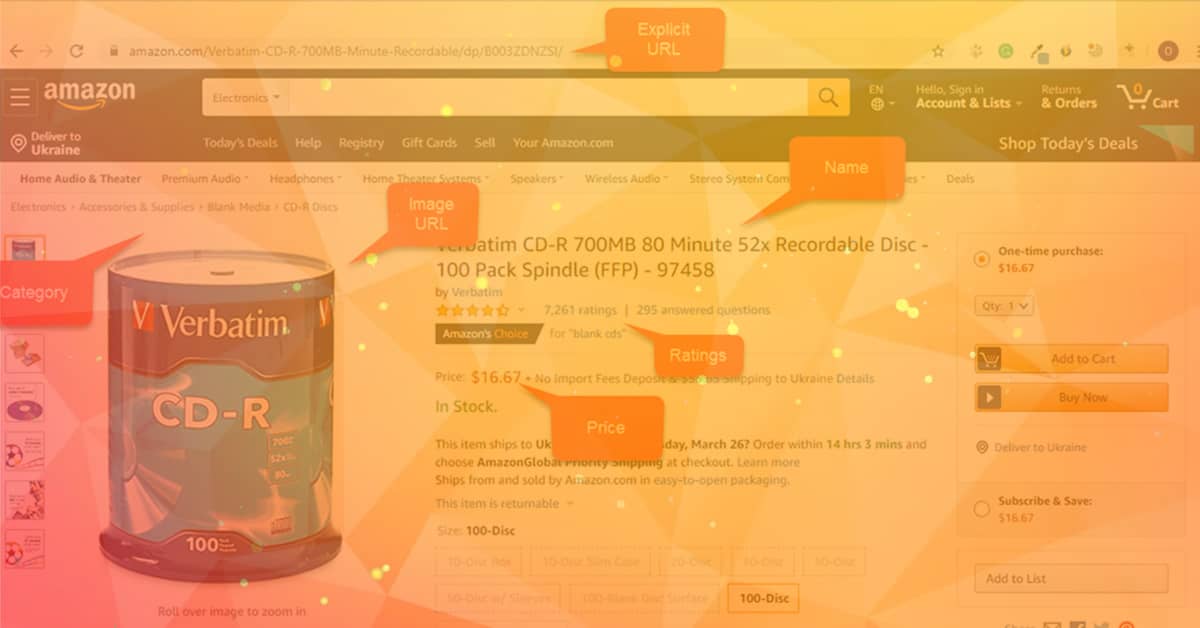
One of the biggest online retailers, Amazon, is growing with each passing day. In terms of market capitalization and total sales, Amazon has become a giant in the eCommerce industry. It has a large amount of data that can be very fruitful for online businesses. Today the online retail industry has seen tremendous growth, with shoppers becoming more willing to buy things online. So much so they have gained the confidence to get smartphones and laptops online. Buyers nowadays head straight to Amazon for online searches, even before Google. As an eCommerce business, your end goal is to convert an online consumer into a loyal customer. Here is where data analytics can help in optimizing your offerings. Imagine how vital Amazon data is for a retailer. There is a big pool of products, news, exclusive deals, ratings, reviews, and much more, and scraping this data can be useful for vendors and sellers.
What are the benefits of scraping Amazon Product Data for eCommerce business?

1. Analyze the products of competitors
Assessing your competitor’s products is an effective way to make the right decisions in business. You make sustainable marketing strategies as Amazon is a host of all the latest information.
2. Review the accumulation of products
Reviews have become one of the most significant factors in determining whether a buyer will go with the purchase or not. When you scrape Amazon product data, you can find out what influences a product’s ranking and use this information to establish effective strategies to improve your product and service.
3. Collecting reviews of competing products
You will also benefit by closely studying your competitor’s product reviews. This can give you a competitive edge over your rivals and create your winning areas.
4. Profile data of customers
Another benefit of Amazon Web Scraping is to collect customer profile data of your target niche. You can create incredible leads with this data. One of the best ways is to scrape the data of Amazon’s best and top reviewers.
5. Gather Market Data
Conducting market data analysis will help you to understand your most loved products. One can also understand the category structure of Amazon and where products stand in the market. Scraping top-rated and best selling product data will give you insights into the ones which are no longer in the top positions.
6. Check product prices
You can scrape competitor prices, check the spot price trends, and identify the best pricing strategies. With strong and effective strategies, you can increase your profits and resolve competition.
7. Opportunity for international sales
eCommerce giant Amazon operates all over the world and has international shipping opportunities. You can scrape Amazon product data that ships abroad. You can identify markets where prices are high and extend to these markets.
8. Gauge competitors' offers
One of the selling points for an eCommerce business is the variety of deals and offers. Getting your hands on your competitor's offers means an opportunity for you to design clever marketing strategies to stay one step ahead.
9. Recognize the target group
Identify your customer database and make the right choices to sell products in that category.
How to scrape Amazon Product Data using Python?

When you run a code to scrape web data, it will send a request to the mentioned URL. In response to that request, the server will send the data and allow you to read the XML or HTML page. Then the code parses the page (HTML or XML) and identifies and extracts the data.
The basic steps to follow for web scraping in Python are:
Let’s learn how to extract Amazon product data using Python
You will first need to have the compatible version of Python (Python 2.x or Python 3.x) with the necessary libraries (BeautifulSoup, Panda, or Selenium) installed. Then you will require a Google Chrome browser and Ubuntu Operating System.
We will now break down the steps
Step 1
Find the URL from Amazon to extract the data such as name, price, ratings, reviews, etc.
Step 2
The next step is to inspect the page to see. For this, right-click on the element and click ‘inspect.’ For example:
When you click on ‘inspect’, you will get a ‘browser inspect box’ like this -
Step 3
Now, find the data you like to extract, such as name, price, rating, etc. This will be in the ‘div’ tag.
Step 4
Write the code now by first creating a Python file. For this, you need to open the terminal in Ubuntu followed by typing gedit
products=[] #List to store name of the product
prices=[] #List to store price of the product
ratings=[] #List to store rating of the product
driver.get("https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&uniq")
Now that we have the code, we can extract the data in
content = driver.page_source
soup = BeautifulSoup(content)
for a in soup.findAll('a',href=True, attrs={'class':'_31qSD5'}):
name=a.find('div', attrs={'class':'_3wU53n'})
price=a.find('div', attrs={'class':'_1vC4OE _2rQ-NK'})
rating=a.find('div', attrs={'class':'hGSR34 _2beYZw'})
products.append(name.text)
prices.append(price.text)
ratings.append(rating.text)
Step 5
Now you need to run the code by using the following command
python web-s.py
Step 6
You can now store this data in your required format. It may vary depending on your requirement. For example, we will store it in a Comma Separated Value (CSV) format. Check out the following lines in the code –
df = pd.DataFrame({'Product Name':products,'Price':prices,'Rating':ratings})
df.to_csv('products.csv', index=False, encoding='utf-8')
And run the code once again. There will be a file named 'product.csv' with the extracted data.
Conclusion
Python can be a great and efficient tool to scrape Amazon product data.