What is Bing Search Result Scraping?
Bing search result scraping refers to the process of programmatically extracting information from the search results provided by the Bing search engine. Instead of doing it by hand on the Bing website, we use special automated tools like Bing Scraper to get specific details like web addresses, titles, short descriptions, and other important information from the search.
A script or bot interacts with the Bing search engine in a way that imitates the actions of a user searching. It sends requests to Bing's servers, receives the search results, and extracts the desired information from the pages.
This automated process allows users to quickly collect large amounts of data from Bing using the SERP Scraper API. It can be helpful for various purposes, such as research, analysis, or building applications that rely on search engine data.
Which are the Methods to Scrape Search Results from Bing?
When you search on Bing, the results page will load dynamically (meaning it changes without refreshing the whole page), and you might need to interact with the page like a real user would. Scraping frameworks are good at handling these situations. They make it easier for your computer program to navigate Bing's website, click buttons, and get the necessary information without doing it all manually.
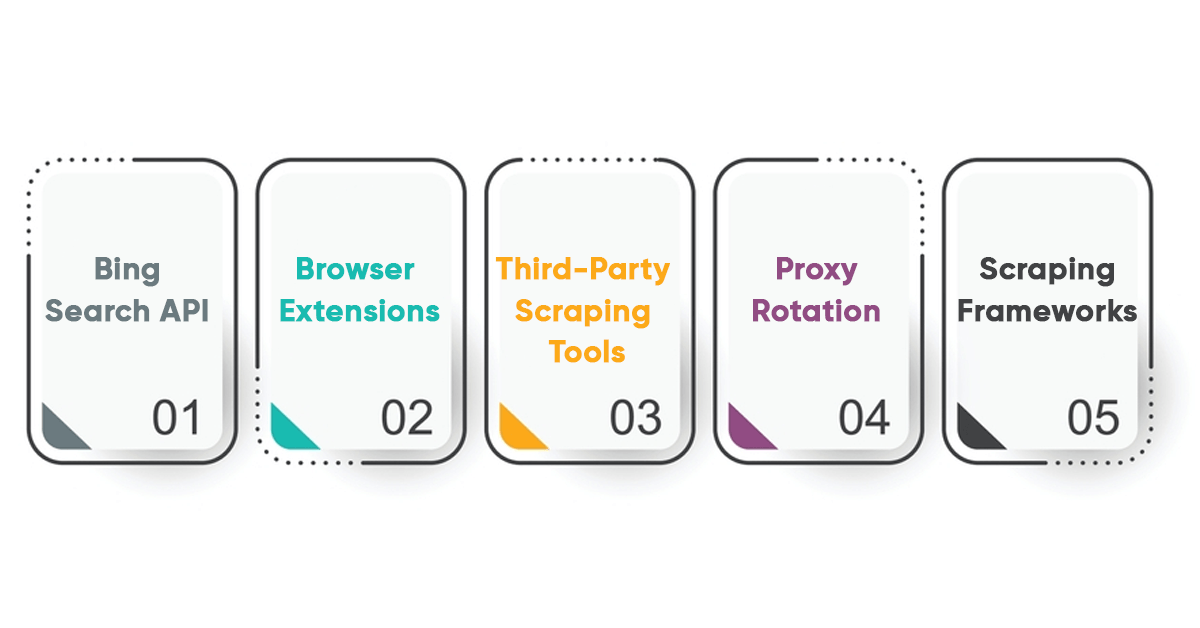
Bing Search API
Bing offers an official API (Application Programming Interface) that allows developers to retrieve search results programmatically in a structured format. This is the recommended and legal way to access Bing's search data, as it adheres to Microsoft's terms of service.
Browser Extensions
Browser extensions can be created to facilitate scraping by running scripts directly within the user's browser. However, these extensions must comply with the browser's extension policies and Bing's terms of service.
Third-Party Scraping Tools
Some third-party tools and services are designed for web scraping, some of which offer point-and-click interfaces for extracting data from Bing search results. Users should exercise caution and ensure such tools' legality and ethical use.
Proxy Rotation
Users can employ proxy servers to rotate IP addresses during scraping Bing SERPs to avoid IP blocks and rate limiting. This helps distribute requests and avoid detection as an automated Bing scraper API.
Scraping Frameworks
Imagine you want to automate tasks on the internet, like collecting information from Bing search results. Scraping frameworks, such as Puppeteer (for Node.js) or Playwright, act like organized tools to help you do this more efficiently. They provide a structured way to automate actions in your web browser.
How to Extract Bing Search Results?
Imagine you want to automate tasks on the internet, like collecting information from Bing search results. Scraping frameworks, such as Puppeteer (for Node.js) or Playwright, act like organized tools to help you do this more efficiently. They provide a structured way to automate actions in your web browser.
Bing SERP scraping results can be scraped by using different methods. It can be done
import requests
easily by utilizing the capabilities of Python.
Step-1: Installing necessary packages
Observe that we have merely imported the requests library. We'll be able to generate network requests thanks to this library. The payload has to be ready next. The above-described query technique will be used to do the search; hence, the following job parameters must be specified:
Step-2: Setting up a payload
payload = {
"source": "bing_search",
"domain": "io",
"query": "oxylabs proxy",
"start_page": 1,
"pages": 10
}
Next, we will use the requests module to submit this payload to the SERP Scraper API. We'll apply the post-method here:
Step-3: Send a POST request.
response = requests.post(
"https://realtime.oxylabs.io/v1/queries",
auth=("USERNAME", "PASSWORD"),
json=payload,
)
An additional parameter called auth is required for the post function, and it takes a tuple object. This tuple object requires that the proper account credentials be entered. The JSON argument is used to send the payload as JSON. The response object is where we also store the outcome. To check if everything is operating as intended, let's output the status code now.
print(response.status_code)
If we run this code, it will print 200 if everything works. Please confirm that you have followed the instructions correctly if you notice a different value. Additionally, confirm that the credentials you used are accurate by validating them. If, in the odd event you see an HTTP 500 error message, our Bing SERP API cannot process the request.
Step-4: Save information to a CSV or JSON file
The data will first be exported as a JSON object. The one line of code that follows can be used to do this:
data = response.json()
The search results will be included in a Python dictionary within the data object, allowing for additional processing. Now let's export the information in JSON format.
We'll utilize the pandas library for this, as indicated below:
import pandas as pd
df = pd.DataFrame(data)
df.to_json("search_results.json", orient="records")
The search results will be stored in a new file called search_results.json that is created in the current directory. The same object can also be used to export the data as a CSV file. In order to do this, we must write as follows:
df.to_csv("search_results.csv", index=False)
The search results will now be created in a new file called "search_results.csv" in the current directory if we execute this.
Pros of Bing Search Results Scraping
Below listed are the Prons of Scraping Bing Search Results:
Data Insights
Scraping Bing search results gives us important information about how people use the internet. This helps us make smart decisions based on real data about what people are interested in, what's popular, and how they search for things.
Market Intelligence
Businesses can get ahead of others by using the scraped data to understand what's happening in the market. They can see what people like, what they don't, and what their competitors do.
SEO Optimization
People who own websites and those who work in SEO (Search Engine Optimization) can use scraped data to determine how well their website is doing in search results. They can also check what other websites are doing to get more visitors.
Content Creation
People who create content, like articles or videos, can use scraped data to know popular topics. This helps them make content that people want to see or read about.
Innovation
Developers, or people who make computer programs, can use and scrape bing search results to create new and cool tools and apps. This helps make using the internet more interesting and helpful for everyone.
Real-Time Analytics
Scraping Bing SERPs in real-time means getting the latest data quickly. This is super important for businesses and others who want to know what's happening right now and stay ahead in fast-changing industries.
Cons of Bing Search Results Scraping
Check out the cons of Bing Search Result Data Scraping:
Legal and Ethical Concerns
Sometimes, scraping Bing search results can break the rules of the search engine. This can get people in trouble and make things not fair for everyone. We should always play by the rules.
Blocked Access
Bing might notice when someone is scraping too much and stop them from getting more information. It's like saying, "Hey, slow down!"
Resource Strain
If someone scrapes too aggressively, it can make Bing's computers work extra hard. This could slow things down for other people trying to use Bing, and nobody likes a slow internet.
Dependency on Bing's Policies
Bing sets the rules, which could affect how scraping works if they change. It's like playing a game, and suddenly, the rules change. It's essential to follow the rules to keep everything fair and square.
Conclusion
Even though web scraping can be a valuable tool for extracting data, it's crucial to approach Bing web scraping responsibly. Users are advised to consider legitimate alternatives like the Bing Scraper API to ensure compliance with legal and ethical standards. If web scraping becomes the chosen method, it must be carried out with a comprehensive understanding of potential risks and a strict adherence to Bing's terms of service. Responsible web scraping contributes to a positive online environment and helps avoid legal consequences.