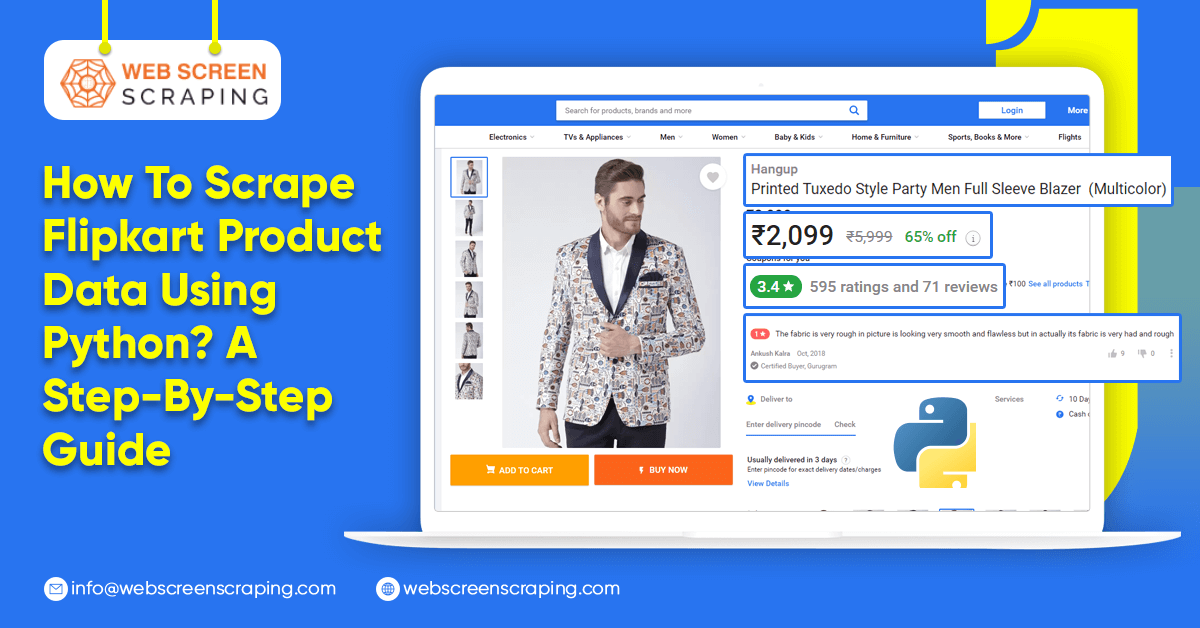
In today's era of digital advancement, the abundance of product details accessible on e-commerce platforms such as Flipkart has emerged as a valuable resource. This is true for firms, researchers, and enthusiasts seeking profound insights.
Extracting data from these platforms can offer a trove of data. Their usage is competitive analysis, market research, price monitoring, and various other purposes. Thus, in this guide, we will delve into the procedures involved in scraping Flipkart product data, a prominent online marketplace in India.
What Is Flipkart Product Data Scraping?
Flipkart is India's top online store selling various items like books, music, electronics, and movies. People can shop on the website or through its phone app.
For firms aiming to use this big data for an edge in competition, extracting product information is vital. While there are different ways to scrape Flipkart product data from the web, using a product data extraction service often meets most business needs.
Web Screen Scraping is a leading firm providing Flipkart product data extraction services. We have the tools and know-how to extract Flipkart product data as continuous feeds, regardless of the industry or purpose.
What Are the Types of Data Which Can Be Scraped?
The data regarding the product consists of a name, description, images, features, etc., and can easily pull-out products from web pages and databases. The webpage is having the most updated and recent information which can be pulled out for the Product Data Extraction Services. Many users hire Flipkart Product Scraper so that we scrape data from different websites. This automatic procedure of data scraping is quick and produces a specific amount of outputs that will match various database platforms.
Flipkart product data scraping helps gather specific details about each product:
- Product Title
- Description
- Regular Price
- Discount Price
- Shipping Price
- Specifications
- Availability
- Brand Name
- Offers & Sale
- Key Features
- Category
- Product Image
- Product URL
- Ratings
- Reviews
How To Scrape Flipkart Product Data Using Python?
Web scraping involves retrieving information from websites through specialized tools or software. Here, Web Screen Scraping comes in handy. Typically, proficiency in computer programming is required, along with the utilization of specific libraries such as BeautifulSoup in Python or other dedicated scraping tools. Platforms like Flipkart implement rules, codes, and structures to prevent or restrict automated data gathering processes.
Here, the question arises: How does Web Scraping work?
When one runs a web scraping code, it sends a request to the specified URL. The server then responds by sending the information, allowing one to read the HTML or XML page. The code takes this HTML or XML page, looks for the data you're interested in, and collects it.
For web scraping using Python, you generally follow these basic steps:
- Identify the URL you want to collect data from.
- Examine the Page.
- Locate the specific data to collect.
- Write the necessary code.
- Execute the code and gather the data.
- Organize and save the data in the structure you need.
Now, let's investigate how to scrape product data from the Flipkart website using Python.
Libraries used in Web Scraping:
Python has different libraries for different tasks. In this demonstration, we will be using the following libraries:
- Selenium: It's a web testing library used to automate browser tasks.
- BeautifulSoup: This Python package helps in parsing HTML and XML documents, making it easier to extract data.
- Pandas: This library is handy for data manipulation and analysis. It helps extract and store data in the desired format.
Now, let us chalk out the pre- requisites:
- Ensure that you have installed either Python 2.x or Python 3.x on your computer.
- Additionally, make sure to have the Selenium, BeautifulSoup, and Pandas libraries installed.
- Also, make sure you have the Google Chrome browser installed.
- Lastly, confirm that you are using the Ubuntu Operating System.
Now, let us begin.
Find the URL you want to gather data from.
In this example, we'll be scraping information about laptops from the Flipkart website, focusing on extracting Price, Name, and Rating. The specific URL we'll be working with is https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&uniqBStoreParam1=val1&wid=11.productCard.PMU_V2.
Inspect the Page.
The information we're looking for is usually hidden within specific tags on the webpage. To find these tags, right-click on the element you want to scrape and select "Inspect." This action allows you to view the underlying code associated with that element.
When you click on the “Inspect” tab, you will see a “Browser Inspector Box” open.
Identify the data to collect
Let's gather the Price, Name, and Rating from specific sections labeled with the "div" tag.
Write the code
To begin, create a Python file. Open the terminal in Ubuntu and type 'gedit
' with a '.py' extension. For instance, let us name the file "web-s". Here's the command:
Now, let’s draft our code within this file.
First, import all the required libraries:
from selenium import webdriver
from BeautifulSoup import BeautifulSoup
import pandas as pd
To configure the web driver for the Chrome browser, set the path to Chromedriver:
driver = webdriver.Chrome("/usr/lib/chromium-browser/chromedriver")
Use the code below to access the desired URL:
products=[] #List to store name of the product
prices=[] #List to store price of the product
ratings=[] #List to store rating of the product
driver.get("https://www.flipkart.com/laptops/~buyback-guarantee-on-laptops-/pr?sid=6bo%2Cb5g&uniqBStoreParam1=val1&wid=11.productCard.PMU_V2")
After opening the URL, it's time to fetch the data from the website. As mentioned earlier, the relevant information is nested within
tags. I'll locate these div tags with their respective class names, extract the data, and save it in a variable.
Refer to the code below:
content = driver.page_source
soup = BeautifulSoup(content)
for a in soup.findAll('a',href=True, attrs={'class':'_31qSD5'}):
name=a.find('div', attrs={'class':'_3wU53n'})
price=a.find('div', attrs={'class':'_1vC4OE _2rQ-NK'})
rating=a.find('div', attrs={'class':'hGSR34 _2beYZw'})
products.append(name.text)
prices.append(price.text)
ratings.append(rating.text)
Run the program and collect data.
To run the code, use this command:
Organize data into the preferred format
After scraping Flipkart product data, you might want to arrange it. You can use different formats based on what you need. In this case, we'll save the gathered data in a CSV format (Comma Separated Values). To do this, we will include the following lines in the code.
df = pd.DataFrame({'Product Name':products,'Price':prices,'Rating':ratings})df.to_csv('products.csv', index=False, encoding='utf-8')
Now, we can run the entire code again.
This will create a file named "products.csv" containing the scraped Flipkart product data.
Conclusion
Extracting Flipkart product data details from Flipkart or any website can provide valuable insights. However, it's essential to do this responsibly by adhering to the website's guidelines. Follow the rules of the website and not put too much strain on their servers by making too many requests.
Additionally, websites may alter their structure or regulations, necessitating adjustments in your data collection methods. Always consider the legality, fairness, and potential impact on the website while gathering data. When conducted ethically, web scraping using Web Screen Scraping can furnish crucial information for various purposes such as market analysis, price comparisons, trend assessment, and more.