In this blog, you will see exactly how we extract Meetup events using Beautiful Soup and Python elegant and effortless manner.
This blog aims to get you started on real-world problem solving while keeping it very simple, that’s the reason you become practical and get familiar outcomes rapidly.
So the first thing you need to keep in mind is that you have installed Python 3 and if not, you must install Python 3 before processing anything.
pip3 install beautifulsoup4
We will require Libraries’ request, lxml, and soupsieve to fetch data, break it down into XML, or use CSS selectors. After that, you can install it.
pip3 install requests soupsieve lxml
Once you installed, you will have to open the editor or type in.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests
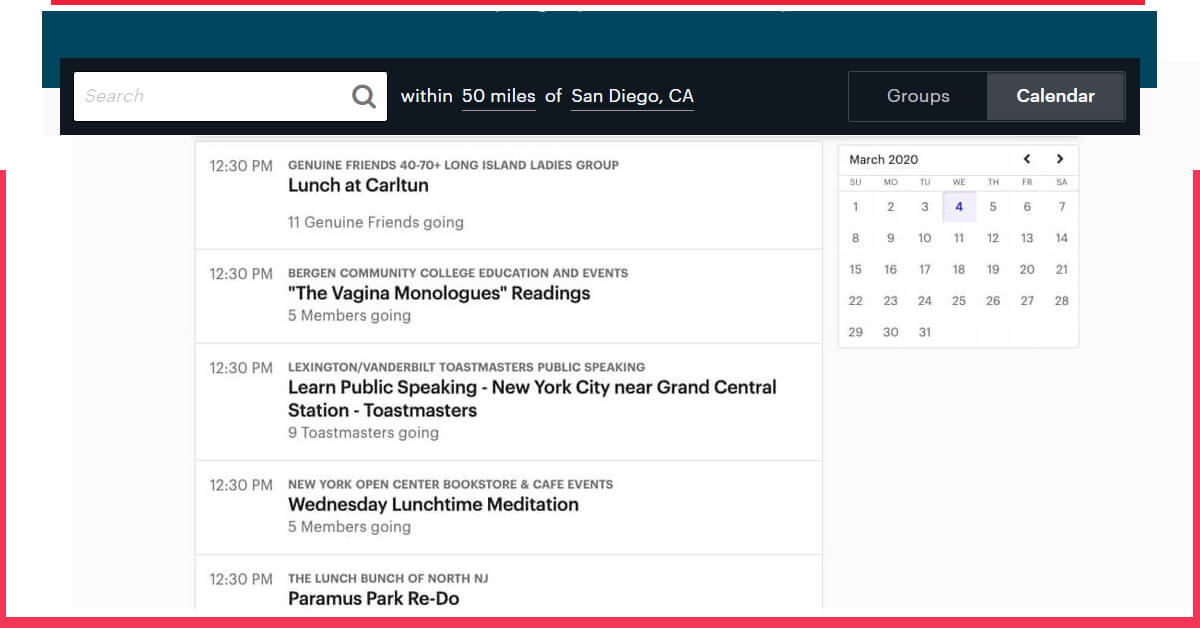
Let’s go to the Meetup event page and review the data we want.
It will display like this
Let’s get back to the code. Let’s try and catch data via pretending we are a browser like this.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.meetup.com/find/events/?allMeetups=true&radius=25&userFreeform=New York, NY&mcId=c10001&mcName=New York, NY'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
Save this as scrapeMeetup.py.
In case, you run it.
python3 scrapeMeetup.py
You will see the whole HTML page.
Then, let’s use the CSS selector to fetch the data we require. To evaluate that you will have to open chrome and inspect the tool.
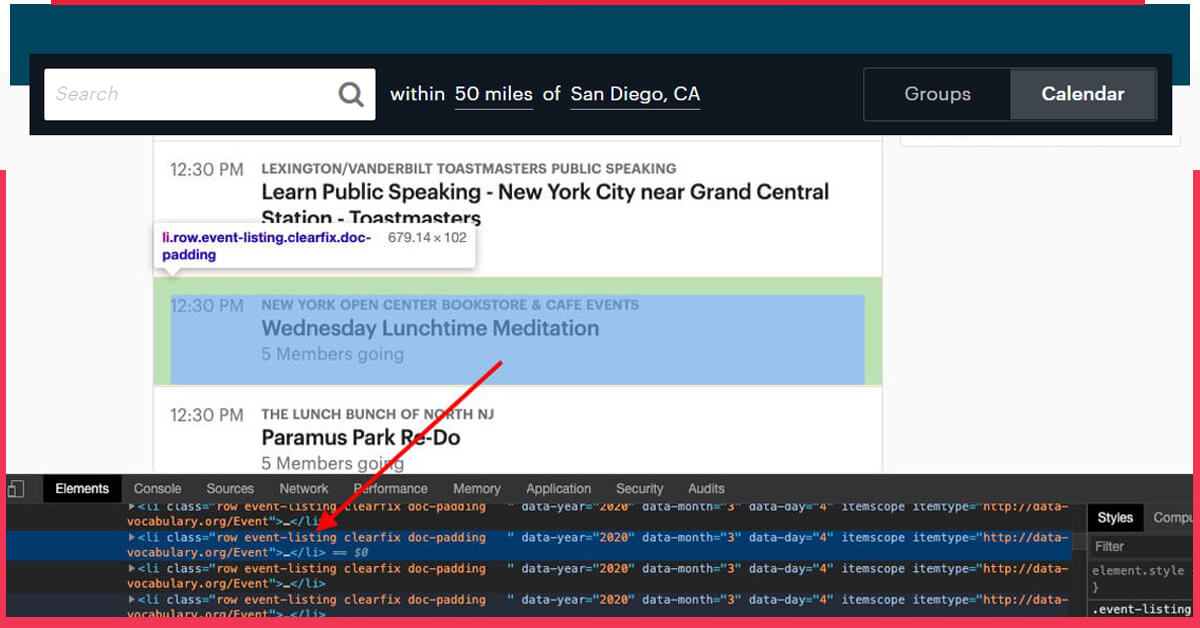
Now, we will notice that all the particular product data are available with the class called ‘event-listing. We extract this utilizing the CSS selector name ‘event-listings. After that, the code will appear like this :-
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.meetup.com/find/events/?allMeetups=true&radius=25&userFreeform=New York, NY&mcId=c10001&mcName=New York, NY'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.event-listing'):
try:
print('----------------------------------------')
print(item)
except Exception as e:
#raise e
print('')
This will imprint all the content in every element that contains product data.
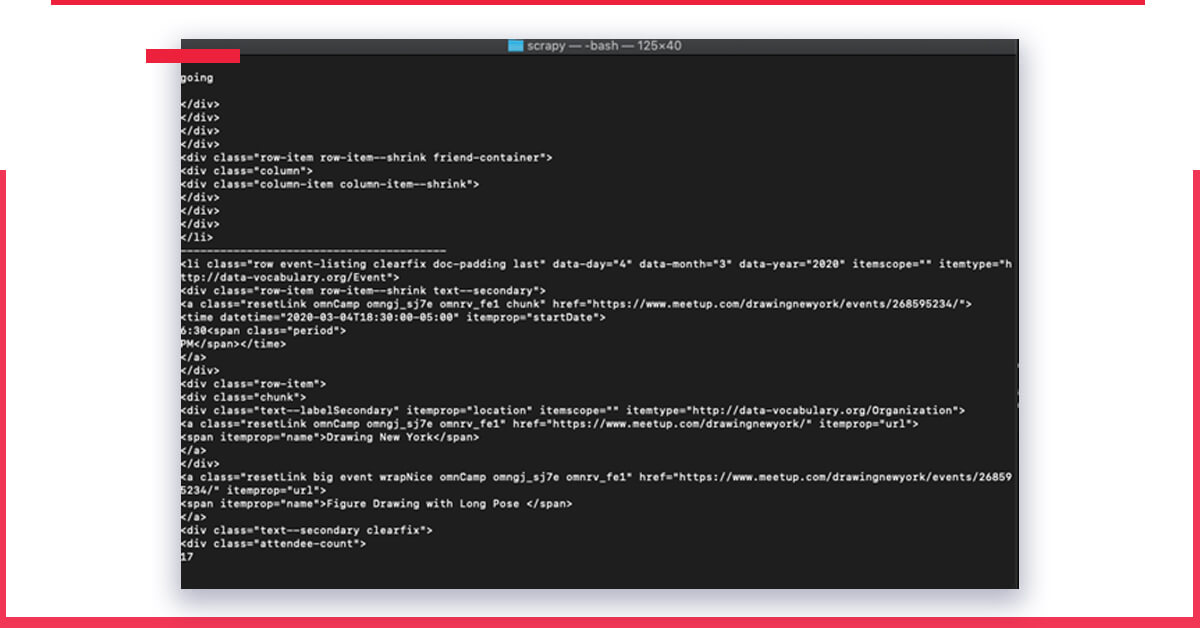
Let’s pick the classes within these rows that comprise the data we need. We observe that a title is a
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.meetup.com/find/events/?allMeetups=true&radius=25&userFreeform=New York, NY&mcId=c10001&mcName=New York, NY'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.event-listing'):
try:
print('----------------------------------------')
#print(item)
print(item.select('[itemProp=name]')[0].get_text())
print(item.select('[itemProp=name]')[1].get_text())
print(item.select('.omnCamp')[0].get_text().strip().replace('\n', ' '))
print(item.select('.attendee-count')[0].get_text().strip().replace('\n', ' '))
except Exception as e:
#raise e
print('')
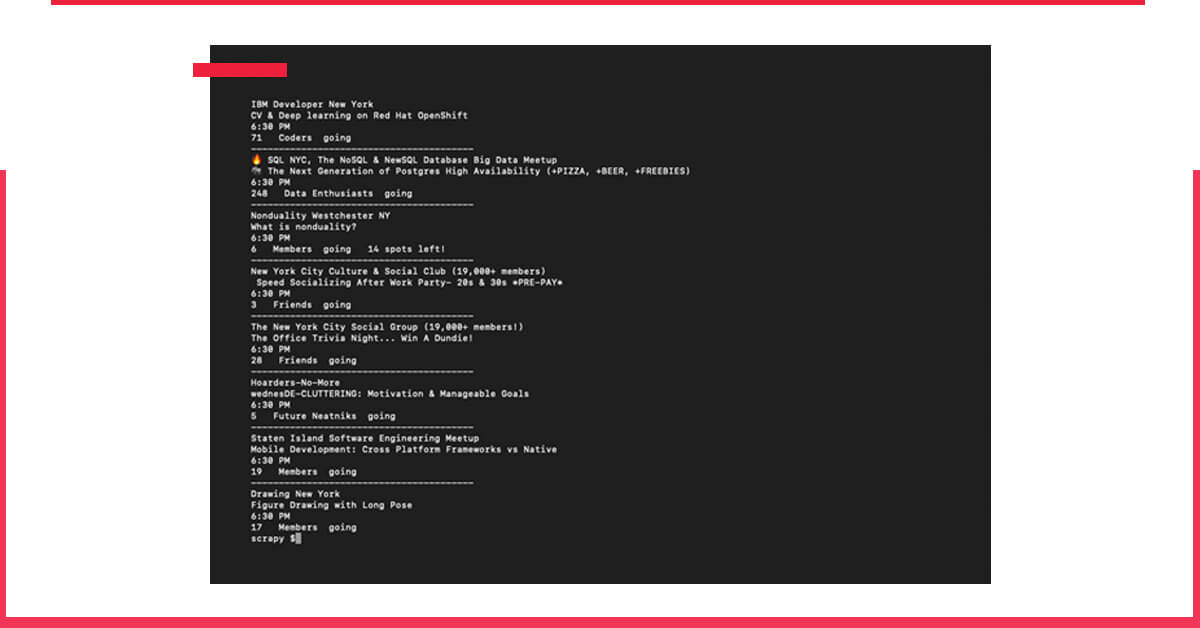
If you run that, it will print out the details
Yeah!! We got everything.
You wish to use that in production or wish to scale thousands of links, you will find that your IP is blocked directly by Meetup. With this situation, rotating proxy services for rotating IPs are necessary. You might use services like Proxies API for routing your calls utilizing millions of occupied proxies.
If you want to scrape the crawling speed and don't require setting up the infrastructure, you might use our Cloud base crawler Web Screen Scraping to easily extract thousands of URLs at great speed from our scraper.