
Scraping Amazon Product Data
As we know, Amazon is one of the biggest e-commerce corporations in the U.S.A. It offers a wide variety of products all over the world. For e-commerce businesses, this means a large amount of data available to meet their needs. Retailers can extract useful information from Amazon and save it in a JSON format or a spreadsheet. They can also automate this process and receive data on a weekly or monthly basis. But there is no simple way to access this avalanche of data for your business requirements. Fortunately, one can use tools like amazon data scraper to extract data using web scraping. But before diving into this, let’s take a closer look at what kind of product we can scrape from Amazon and its benefits.
What kind of product data can be scraped from Amazon.com?
We can extract the following data from Amazon’s website –
- Name of the product
- Price
- Ratings
- Reviews
- Product Description
- Image URLs
- Variant ASINs
- Link to Review Page
- Sales Rank
What are the benefits of scraping Amazon Product Data?
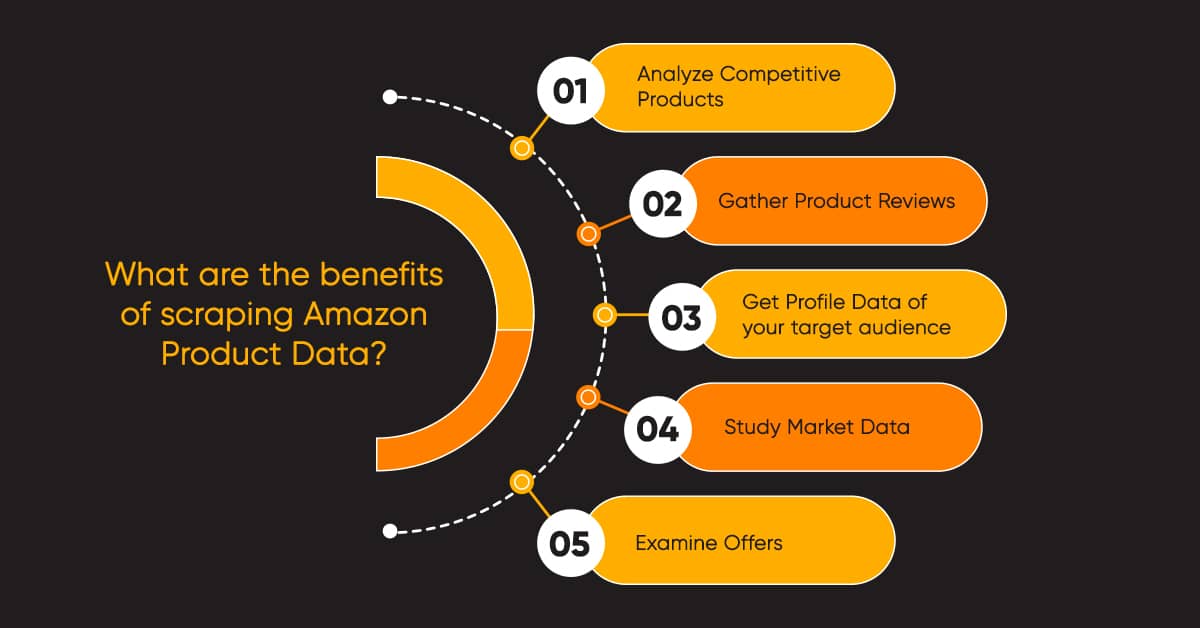
Web scraping enables you to focus on competitors’ product prices, cost monitoring in real-time, and seasonal shifts and, in turn, give your clients better product offers. The following are some of the benefits of scraping Amazon product data –
Analyze Competitive Products –
This is one of the most important parts of making decisions in business. Getting your hands at competing products equips you to design better marketing strategies. On Amazon, you will get all the latest information on products. You can scrape this product data and compare and track the changes.
Gather Product Reviews –
Businesses need to know how their products are doing in the market. Scraping product data allows you to identify factors that are influencing product ranking. As a result, you can measure and improve your products or services.
Get Profile Data of your target audience –
You can scrape data from Amazon’s top reviewers and offer them to review your products, already in the market, or any newly launched ones. On such a huge platform, it is obvious that the list of top reviewers would be gigantic. Here is where web scraping helps to get the exact data you need.
Study Market Data –
Understanding market data will help you recognize products that are in demand. You can then determine your most promising niche.
Examine Offers –
One of the most attractive factors for buyers is an offer they can not refuse. When you know what your rivals are offering, you get in a position to make better marketing decisions for your products.
How can you scrape Amazon Product Data using BeautifulSoup?

To begin, we will need some basic requirements in place. Python has a collection of libraries that facilitate data scraping with ease. So, you can start by first installing Python in your system. Here, we will use the example of Beautiful Soup which is one of the libraries for Python. This library is super-efficient and easy to use for web scraping. Once you install Python, you can install Beautiful Soup from -
pip install bs4
Besides this, you will need a good web browser like Mozilla or Google Chrome and a basic understanding of HTML tags. Let’s begin -
Firstly, create a User-Agent: Like many websites, Amazon also has protocols that would block bots from accessing their data. Hence, to extract your data, you need to create a User-Agent, a string that indicates to the server what type of host is requesting. Following is a User-Agent example -
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
Next, send a request to a URL: You can send a request to the webpage to access its data like this -
://www.amazon.com/Sony-PlayStation-Pro-1TB-Console-4/dp/B07K14XKZH/" webpage = requests.get(URL, headers=HEADERS)
As you can see, the requested webpage shows an Amazon product. Python script will focus on extracting information like the name of the product, the latest price, etc.
Now, let us create a soup of information: There will be a response by the website on the webpage variable. Then the response and the type of parser are sent to the Beautiful Soup function, which will look like this -
soup = BeautifulSoup(webpage.content, "lxml")
“lxml” is a parser used by Beautiful Soup that breaks down the HTML page into Python object. There are four types of Python objects:
- Tag – This refers to the HTML or XML tags with names and other features.
- NavigableString – This is the text stored within a bag.
- BeautifulSoup – This is the parsed document.
- Comments – These are the unwanted pieces of an HTML page that are not in the above categories.
Furthermore, one of the most tedious tasks of extracting data is discovering the precise tags and ids you want. For this, you use a web browser. Open the webpage in your browser and inspect the element by clicking right, and a pane will open on the right side of the screen shown below -
After obtaining the tag values, it is easy to extract the data. Use the ‘find ()’ function to look for specific tags and attributes of a product and locate the Tag Object, which has the “title of the product.”
Outer Tag Object
title = soup.find("span", attrs={"id":'productTitle'})
Now take the NavigableString Object.
# Inner NavigableString Object title_value = title.string
Lastly, strip the excess spaces and convert the object into a string value.
# Title as a string value title_string = title_value.strip()
Here, you can look at the types of each variable by using “type ()”.
# Printing types of values for efficient understanding
print(type(title))
print(type(title_value))
print(type(title_string))
print()
# Printing Product Title
print("Product Title = ", title_string)
Results:
<class 'bs4.element.Tag'> <class 'bs4.element.NavigableString'> <class 'str'> Product Title = Sony PlayStation 4 Pro 1TB Console - Black (PS4 Pro)
Similarly, you can figure out the tag values for different product details such as “price of the product” or “customer ratings.”
Below is the Python script that displays information such as “title of the product”, “price of the product”, “ratings of the product”, “the number of customer reviews”, and “product availability.”
from bs4 import BeautifulSoup
import requests
# Function to extract Product Title
def get_title(soup):
try:
# Outer Tag Object
title = soup.find("span", attrs={"id":'productTitle'})
# Inner NavigableString Object
title_value = title.string
# Title as a string value
title_string = title_value.strip()
# # Printing types of values for efficient understanding
# print(type(title))
# print(type(title_value))
# print(type(title_string))
# print()
except AttributeError:
title_string = ""
return title_string
# Function to extract Product Price
def get_price(soup):
try:
price = soup.find("span", attrs={'id':'priceblock_ourprice'}).string.strip()
except AttributeError:
price = ""
return price
# Function to extract Product Rating
def get_rating(soup):
try:
rating = soup.find("i", attrs={'class':'a-icon a-icon-star a-star-4-5'}).string.strip()
except AttributeError:
try:
rating = soup.find("span", attrs={'class':'a-icon-alt'}).string.strip()
except:
rating = ""
return rating
# Function to extract Number of User Reviews
def get_review_count(soup):
try:
review_count = soup.find("span", attrs={'id':'acrCustomerReviewText'}).string.strip()
except AttributeError:
review_count = ""
return review_count
# Function to extract Availability Status
def get_availability(soup):
try:
available = soup.find("div", attrs={'id':'availability'})
available = available.find("span").string.strip()
except AttributeError:
available = ""
return available
if __name__ == '__main__':
# Headers for request
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
# The webpage URL
URL = "https://www.amazon.com/Sony-PlayStation-Pro-1TB-Console-4/dp/B07K14XKZH/"
# HTTP Request
webpage = requests.get(URL, headers=HEADERS)
# Soup Object containing all data
soup = BeautifulSoup(webpage.content, "lxml")
# Function calls to display all necessary product information
print("Product Title =", get_title(soup))
print("Product Price =", get_price(soup))
print("Product Rating =", get_rating(soup))
print("Number of Product Reviews =", get_review_count(soup))
print("Availability =", get_availability(soup))
print()
print()
Results:
Product Title = Sony PlayStation 4 Pro 1TB Console - Black (PS4 Pro) Product Price = $473.99 Product Rating = 4.7 out of 5 stars Number of Product Reviews = 1,311 ratings Availability = In Stock.
This is how you can extract data from a single webpage of Amazon. The script can be further applied to many web pages to get your information. All you have to do is alter the URL.
Closing thoughts
Web scraping is invaluable in the e-commerce business. From getting your hands on comparing product prices or analyzing consumer behavior, you can get great insights to take your business to the next level. With the accessibility of the internet and ease of using Python language, anyone can benefit from web scraping.