
Zillow stands as the leading real estate website in the United States. It serves as the go-to platform for people searching for homes, assessing property values, and connecting with real estate agents. The website has approximately 200 million monthly visitors. With such a high amount of traffic, it is needless to say that websites carry vast information for real estate professionals. However, to take benefit of all this data, you need reliable web scraping services. In this article, we will provide you with an in-depth demonstration of how to use Python to scrape Zillow data for the growth of your business. So, let’s get started.
What Is a Zillow Web Scraping?
Professional Zillow web scraping is extracting Zillow data from its website. It is one of the largest real estate markets that provide information on properties including their listings, prices, descriptions, and more. People can use web scraping techniques to collect the following data:
- Property Listings
- Property Features
- Location data
- Price History
- Market Trends
- Property Images & Virtual Tour
- User Reviews & Ratings
- Agent Information
- Comparative Market Analysis (CMA) Data
- Foreclosure Listings
Extracting the above information from Zillow can be beneficial for numerous reasons. One of the main reasons is it will provide you with valuable insights that will help you make informed decisions for your business.
Benefits of Zillow Data Scraping
Before proceeding further and knowing how to scrape Zillow data, you know that extracting the above offers many advantages in the dynamic world of real estate. Here are some key benefits:
Analyze Marketing Trends
With Real Estate Data Scraping, you can closely monitor and analyze market trends. This includes tracking changes in property prices, rental rates, and demand patterns. This valuable information empowers you to make well-informed decisions, whether you are a buyer, seller, investor, or real estate professional.
Competitor Analysis
Understanding your competitor’s is crucial in any industry, and real estate is not an exception. As per the research, businesses that regularly analyze competitors' data are 2.5 times more likely to outperform their competitors. Scraping Zillow data allows you to keep a close eye on your competitors in the market. Collecting data on your competitor's property listings, pricing strategies, and customer reviews can gain valuable insights about your competitor. All these insights help you adjust your approach and stay competitive in the market.
Find Potential sellers and Buyers
Data scraping is a helpful tool for people who own real estate businesses. It helps you find potential sellers and buyers by gathering their contact info, property listings, and other essential details. This makes it easier to reach out to interested people. For example, you can find homeowners who have just put their homes up for sale and probably need a real estate agent. This can really help you get more leads.
Gaining Competitor Insights
Real estate data scraping can give you deep insights into your competitors' activities. For instance, you can track how frequently your competitors update their property listings and whether they tend to lower or raise prices. This information can be valuable in understanding market dynamics and successful competitors' strategies. Statistically, businesses that use competitive intelligence data see a 10% increase in revenue.
Identify Potential Investment Opportunities
Investors can benefit from real estate data scraping by identifying potential investment opportunities. Investors can make well-informed decisions by monitoring data on foreclosures, distressed properties, or emerging neighborhoods. For instance, by scraping data on property auctions, you can identify properties available at below-market prices, increasing your chances of finding profitable investments. In 2023, 30% of real estate investors found their most profitable investment through data-driven insights.
Assess The Risk Associated With Real Estate Investment
Real estate data scraping helps gather past information about property sales, how the market was doing, and how prices changed over time. This information can be handy for evaluating the safety of investing in real estate. For example, by looking at how prices have increased and decreased in a certain area, you can determine if it's a secure or risky place to invest in. People who carefully check these risks are better at making good investment choices and are less likely to lose money.
Personalized Marketing Campaign
Real estate data scraping helps businesses make unique marketing plans. For instance, by collecting details about properties and what buyers like, you can make marketing materials that suit what buyers want. Customized marketing plans work better and have a 14% higher chance of success than general ones. Adding real estate data scraping to your business strategy can make your business stand out, help you make better choices, and target customers better in the changing real estate market.
Challenges of Zillow Data Scraping
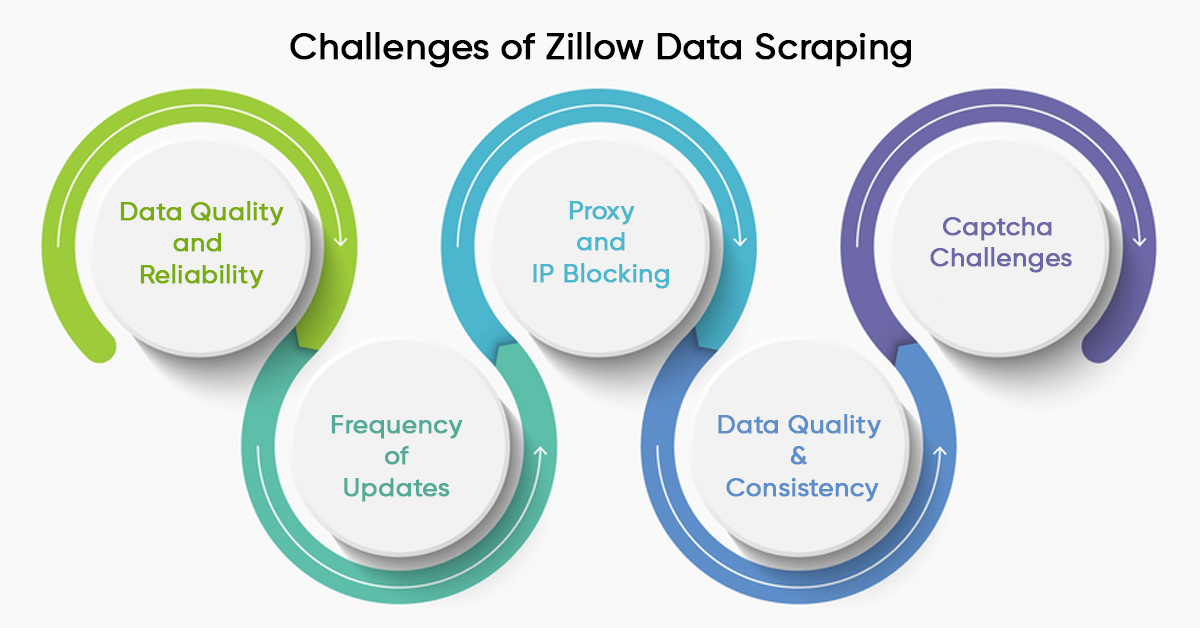
Real estate data scraping has its fair share of challenges that can make this task complex and demanding. Here are some of the primary challenges associated with real estate data scraping:
- Data Quality and Reliability: Real estate data can be inconsistent, outdated, or inaccurate. Scraped data may require extensive cleaning and validation to ensure its reliability for analysis or decision-making.
- Proxy and IP Blocking: Websites may employ security measures like IP blocking to prevent excessive scraping. This can lead to being temporarily or permanently banned from accessing the site if not appropriately managed.
- Captcha Challenges: Some websites employ CAPTCHA tests to prevent automated scraping. Overcoming these tests requires additional techniques, such as CAPTCHA-solving services or manual intervention, which can increase the complexity of scraping.
- Frequency of Updates: Real estate data changes frequently due to new listings, price fluctuations, and property status updates. Maintaining an up-to-date dataset through regular scraping can be resource-intensive.
- Data Quality & Consistency: Real estate data available online can be highly unstructured and inconsistent. Property listings may have varying formats, incomplete information, or errors. Scraping such data requires robust data cleaning and normalization processes.
How to Scrape Data From Zillow Using Python
We will use Python to interact with the Zillow website to scrape Zillow data. However, keep in mind that web scraping can violate a website’s terms and services, so it is important to check Zillow’s terms and conditions before scraping. Additionally, scraping too aggressively or without permission can lead to IP bans or legal issues.
Assuming you are scraping Zillow’s public listing responsibly and within their terms, here is a step-by-step guide on how to scrape data from Zillow using Python:
Install Necessary Libraries
You will need a few Python libraries to perform web scraping. Install them using pip if you have not already:
```bash pip install requests beautifulsoup4
Import the Libraries
Import the necessary libraries in your Python script. Use the below command to import the libraries of your choice:
python import requests from bs4 import BeautifulSoup
Send a GET Request
Use the `requests` library to send a GET request to the Zillow URL you want to scrape. You can specify search filters and parameters in the URL.
```python
url = "https://www.zillow.com/homes/for_sale/New-York-NY_rb/"
headers = {
"User-Agent": "Your User-Agent String" # Use a valid User-Agent header
}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print("Failed to retrieve the webpage")
```
Replace “Your User-Agent String” with an appropriate user-agent header to mimic a web browser.
Parse the HTML Content
Use BeautifulSoup to parse the HTML content of the page:
Python soup = BeautifulSoup(response.content, 'HTML.parser')
Locate and Extract Data
Use BeautifulSoup to locate and extract the data you want from the HTML structure. You can use developer tools in your web browser to inspect the page and identify the needed HTML elements. For example, to extract the titles and prices of listings:
```python
listings = soup.find_all('article', class_='list-card')
For listing in listings:
Title = listing.find('h3', class_='list-card-title').text
price = listing.find('div', class_='list-card-price').text
print(f"Title: {title}\nPrice: {price}\n")
```
Adapt this code to extract other data you are interested in, such as property details, addresses, or URLs.
Pagination
If the listings are spread across multiple pages, you may need to scrape multiple pages by changing the URL and repeating steps 3-5. You can usually find pagination controls on the Zillow website.
Store the Data
Depending on your requirement, you can store the scraped data in a CSV file, database, or any other suitable format.
Final Thought
The dynamic realm of online real estate is undergoing swift transformation, marked by the emergence of fresh services and tools. Zillow, in particular, has experienced remarkable growth in recent years, solidifying its position as a prominent player in the global real estate domain. At its core, Zillow’s primary business model revolves around equipping users with valuable insights into available homes for sales, housing market dynamics, and an array of related data. Having scraped the Zillows’s data, the next step is to figure out how to use that info effectively.