
Web scraping is about gathering information from different websites. The information you collect may assist us in improving the user experience. Your clients might shift to your competitors and will not remain loyal anymore. For instance, your online store sells software. Businesses must be aware of ways to make their product better. To do this, you will need to research software vendors' offerings by visiting their websites. Once you have done that, you may also look up the prices of your competitors. Finally, you can choose how much you will charge for your program and which features need upgrading. Any product can use this procedure.
In this period of intense competition, businesses employ every strategy at their disposal to gain an advantage. Web scraping is the particular instrument that companies can use to win this game. But there are still challenges in this field as well. Websites use different anti-scraping technologies and methods to prevent your crawlers from scraping their content. However, there is always a workaround.
Anti-Scraping
Web scraping bots are frequently blocked using anti-scraping techniques, which prevent the information they collect from being publicly accessed.
Although web scraping has been a successful and affordable method for companies to meet data acquisition demands, spiders and anti-bots are constantly engaged in a coding battle. The main reason is that the whole website might crash due to web scraping. Because of this, some websites employ various anti-scraping techniques to deter scraping activity.
Techniques of Anti-Scraping
1. IP

IP tracking is one of the simplest ways for a website to identify web scraping activities. The website can determine whether the IP is a robot based on its activities. When a website notices that a single IP address is sending an excessive number of requests frequently or in a short time, it is probable that the IP will be blocked since it is a bot. In this situation, the quantity and regularity of visits per unit of time are what are most important for creating an anti-scraping crawler.
Bypass IP address-based blocking
We discovered that web scraping could get around IP address-based restrictions by changing the IP addresses from which the queries reach the target websites. By designating a different proxy server from the pool for each request, it is possible to achieve this by making it appear that the request originated from another user. Various methods can choose the proxies.
2. Captcha
Have you ever visited a website and seen this kind of picture?
You must click "I'm not a robot" to confirm.

Need to choose particular images
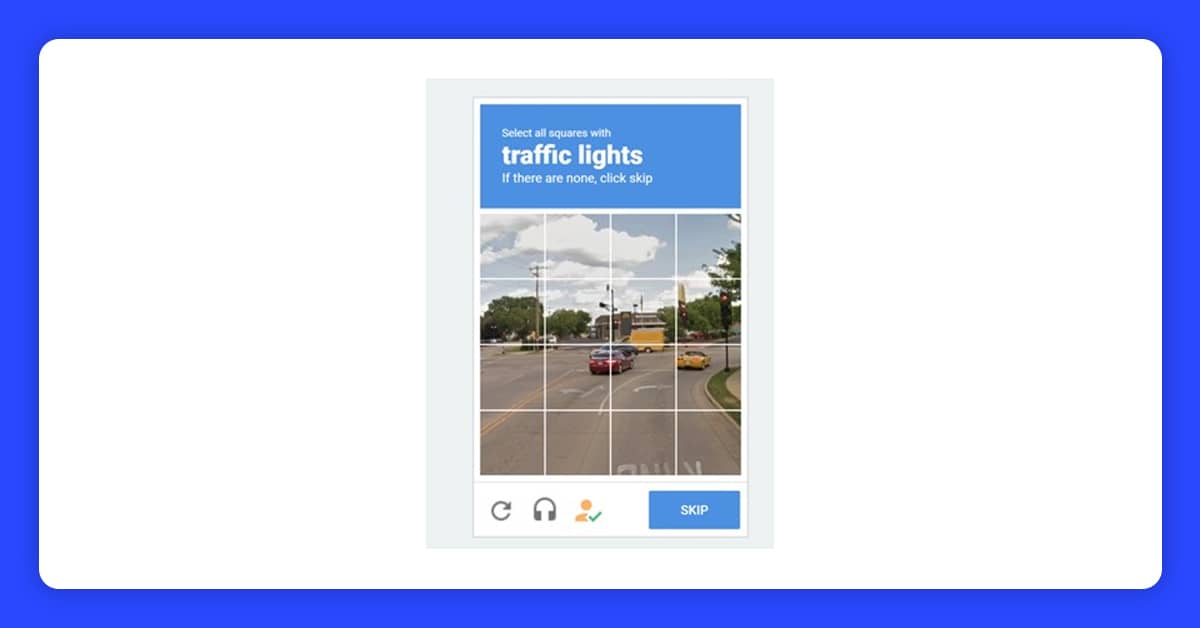
You must enter or choose the correct string.

What is Captcha?
Entirely Automated Public Turing Test to Tell Computers and Humans Apart is a captcha. A public automated program can tell whether a user is a robot or a human. This program would present various problems, including distorted visuals, fill-in-the-blanks, and even equations that supposedly only human beings can solve. These pictures are known as captchas.
This test has been developing for a while, and many websites are now using Captcha as an anti-scraping method. Directly passing Captcha used to be complicated. However, several open-source solutions are now available that tackle Captcha issues, even though they might need more sophisticated coding abilities. Some people even develop feature libraries and image recognition methods using machine learning or deep learning approaches to pass this test.
How can I use web scraping to solve Captcha?
Avoiding it is more straightforward than dealing with it.
The easiest way for most people to avoid the Captcha test is to slow down or randomize the extraction process. Effective ways to lower the likelihood of triggering the test include adjusting the delay period or using rotating IPs.
Check out the methods we've listed to crack the CAPTCHA if you're using Web Screen Scraping.
3. Log in
Many websites, mainly social media sites like Facebook and Twitter, only display content once you are check-in. The crawlers must also imitate the logging stages to crawl sites like this.
A cookie is a discrete piece of information used to store user browsing information. The crawler must save the cookies after logging into the website. The website would forget that you have logged in without the cookies and prompt you to do so again.
Additionally, some websites with strong scraping controls might only permit limited access to the data, like 1000 lines per day, even after logging in.
Your bot must be able to log in.
- The crawler should act out the login procedure, which entails using the mouse to click the text box and "log in" buttons or using the keyboard to enter the account and password information.
- Websites that permit cookies would save the users' cookies to remember them. Save the cookies first, then log in. With the help of this method, your crawler could skip time-consuming login procedures and scrape the data you require. Shortly, revisiting the website won't be necessary, thanks to these cookies.
- Suppose you unluckily come across the aforementioned stringent scraping measures. In that case, you might program your crawler to check the page regularly, such as once daily—plan for the crawler to collect the most recent 1000 lines of data at regular intervals.
4. UA
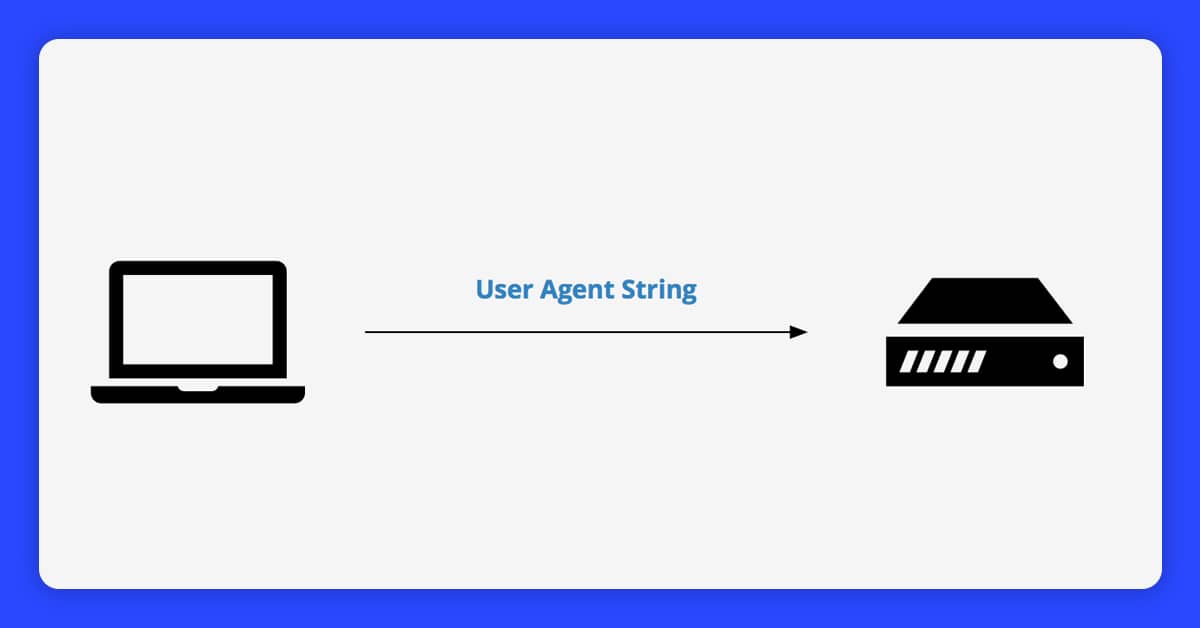
User-Agent, or UA for short, is a header used by websites to determine how users interact with them. It includes details on the operating system and its version, the type of CPU, the browser and its version, the browser language, a browser plug-in, and other things.
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) is an example of a UA. AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11
If your crawler does not contain any headers when scraping a website, it will just identify itself as a script (e.g., if using python to build the crawler, it would state itself like a python script). Websites would undoubtedly reject the script's request. In this situation, the crawler has to pose as a browser with a UA header to access websites.
Even if you enter a website with the same URL, various browsers or versions sometimes display different pages or information. There's a chance that the material is only accessible through one browser and restricted by the others. Therefore, it would be necessary to use a variety of browsers and versions to ensure that you can access the correct website.
Change your web browsers to prevent being blocked.
Alternate the UA data till you find the proper one. If a user uses the same UA for an extended time, some sensitive websites that employ sophisticated anti-scraping measures may even restrict access. In this scenario, you would require routine UA information changes.
5. AJAX
AJAX, which stands for Asynchronous JavaScript and XML, is a method for synchronizing the webpage. When only minor page changes occur, the entire website does not need to refresh. AJAX is used more frequently than conventional web development methods to create websites.
How could you tell if an online resource uses AJAX?
Without AJAX, even a minor modification to a website would cause the entire page to rewrite. Typically, a loading icon and a new URL would emerge. We could take advantage of the mechanism for these websites and look for a trend in how the URLs would change.
Instead of training your crawler to traverse websites like people, you could construct URLs in bulk and directly extract information using these URLs.
AJAX-enabled websites only update the area where you click; a loading icon does not display. The site URL will not typically change; therefore, the crawler must handle it.
How is AJAX handled with web scraping?
Particular strategies are required to identify specific encrypted ways on some complicated AJAX-built websites and retrieve the encrypted data from those websites. This issue may take some time because various pages utilize different encryption techniques.
Conclusion
Web scraping and anti-scraping technologies advance daily. When you read this post, these methods may already be obsolete. You could always turn to Web Screen Scraping for assistance, though. Our goal at Web Screen Scraping is to make data available to everyone, especially people without technical backgrounds. As a web-scraping tool, we can offer ready-to-deploy solutions for these five anti-scraping strategies. Please contact us if you require a robust web-scraping solution for your company or project.
Are you looking for the best web scraping services to stay ahead of the competition? Contact Web Screen Scraping today!
Request for a quote!